Are you sure you don't have a key error in your file?
I scratch my head almost every time I see "KeyError: [title]" and I'm almost certain I made no mistake. But every time, it turns out there is some mistake.
Look at my simple mistake, for example.
Here, the command line indicates something is wrong with my "title":
Indeed, in my .csv file, I wrote "Title" with a capital "T," not "title" in lowercase: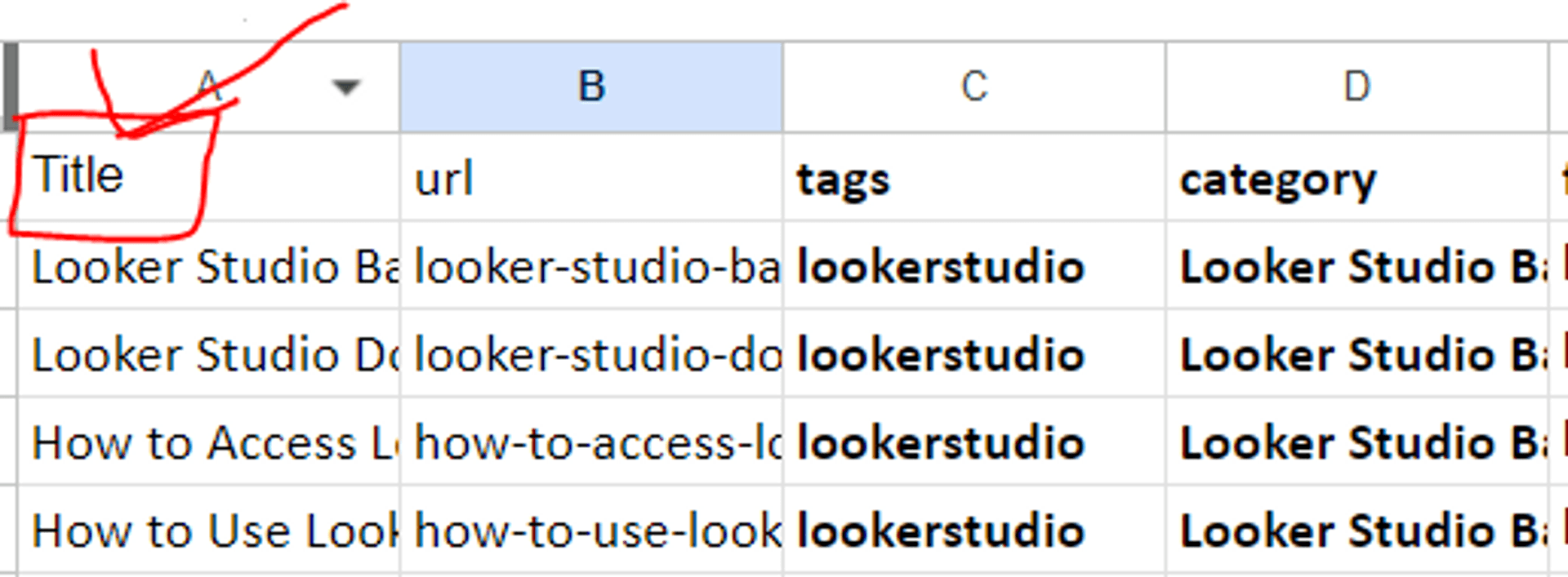
In my script, I used lowercase "title":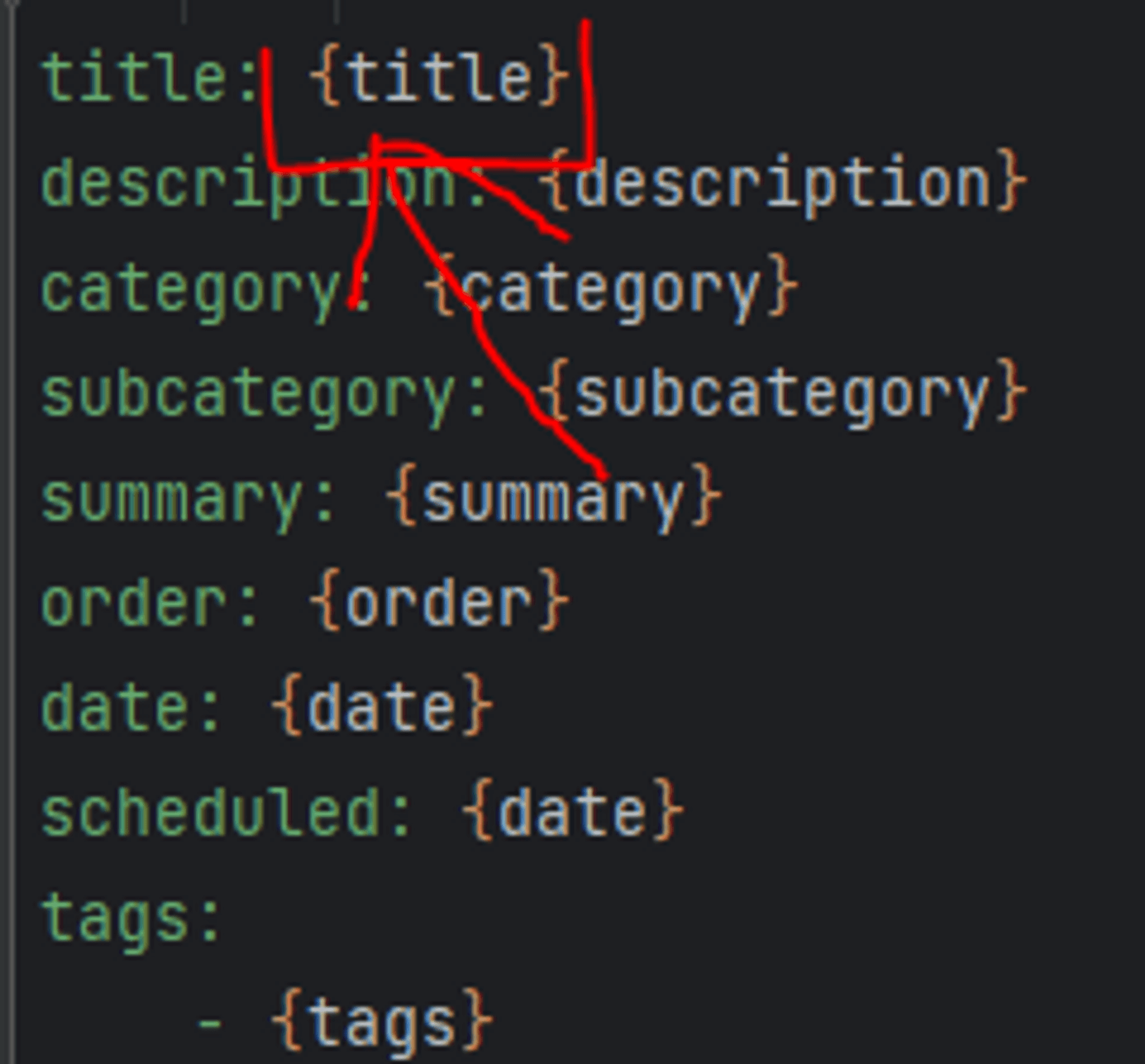
How to Resolve the Pandas KeyError: A Comprehensive Guide
In the world of data manipulation and analysis, pandas is an invaluable tool that helps streamline complex operations. However, for beginners and even seasoned users, errors such as the KeyError are common. This article will delve into what triggers the KeyError, how to troubleshoot it effectively, and how to avoid this error in the future.
What is a KeyError?
The KeyError in pandas occurs when you attempt to access a column or index that doesn’t exist in your DataFrame. For example, you may be referencing a column name that is misspelled or doesn’t exist in the dataset you're working with. It’s one of the most common errors users encounter, and the typical output in the command line looks like this:
KeyError: 'column_name'This error can be frustrating, especially when you’re confident that the column exists. I personally encountered this error when working on a large dataset for a project, and after some investigation, I realized that my column name had an extra space at the end, making it different from the expected column. Catching such details can often prevent KeyErrors.
Causes of the KeyError
The KeyError typically arises from one of the following scenarios:
Misspelled Column Name: The most common cause is a simple typo or capitalization mismatch. Column names are case-sensitive in pandas, so ‘Name’ is different from ‘name’.
Missing Columns: You may be working with a subset of your original DataFrame or a filtered DataFrame where the column you expect no longer exists.
Whitespace or Special Characters: Invisible characters, such as trailing spaces or underscores, can sometimes cause pandas to misinterpret column names.
Inappropriate Indexing: Accessing columns using
.loc[]or.iloc[]with an incorrect index label or position can trigger the KeyError.
How to Troubleshoot and Solve the KeyError
To effectively troubleshoot and resolve the KeyError, follow these steps:
1. Check Column Names
Ensure that the column name exists and is correctly spelled. A good way to see all the available column names is by using:
print(df.columns)2. Strip Whitespace and Correct Typos
Sometimes, column names contain trailing spaces or invisible characters. To avoid this, you can use the .strip() method:
df.columns = df.columns.str.strip()This method will remove any unwanted leading or trailing spaces from all column names.
3. Handle Missing Columns Gracefully
If you’re unsure whether a column exists, you can use the .get() method, which allows you to check for a column and return a default value (e.g., None) if the column doesn’t exist:
df.get('column_name', 'default_value')4. Use Try-Except for Error Handling
In some cases, you may want your script to continue running even if a column is missing. Using a try-except block can help you handle errors gracefully:
try:
df['column_name']
except KeyError:
print("Column not found!")How to Avoid the KeyError
Ensuring that your workflow is smooth and error-free is crucial for maintaining productivity in your data projects. To avoid this common error in the future, consider the following tips:
- Double-Check Column Names: Be cautious of typos and case sensitivity when working with pandas.
- Use Consistent Naming Conventions: Stick to a consistent naming convention (e.g., lowercase names with underscores) to minimize confusion.
- Clean Your Data: Removing unwanted whitespace and standardizing column names at the start of your project will help prevent KeyErrors.
- Always Check DataFrame Structure: Regularly inspect your DataFrame structure using
df.info()ordf.head()to ensure you’re aware of the available columns and data types.
Conclusion
The pandas KeyError is a common stumbling block, especially for those new to data analysis. By understanding its causes and learning how to troubleshoot it, you can avoid this error and keep your workflow uninterrupted.
By following these guidelines, you’ll not only resolve this error efficiently but also avoid it in the future, ensuring a smoother, more productive experience with pandas.
Published